Generative AI
You have most recently heard of 'Generative AI' this is a subset of Machine Learning technology which has become one of the most used buzzwords in tech circle's and beyond. Generative AI is everywhere right now. But what exactly it is ? How does it works ? The concept of AI itself bring up the fear for humans to get replaced by AI, so how can we make most use of it to make our life's (Jobs) easier?
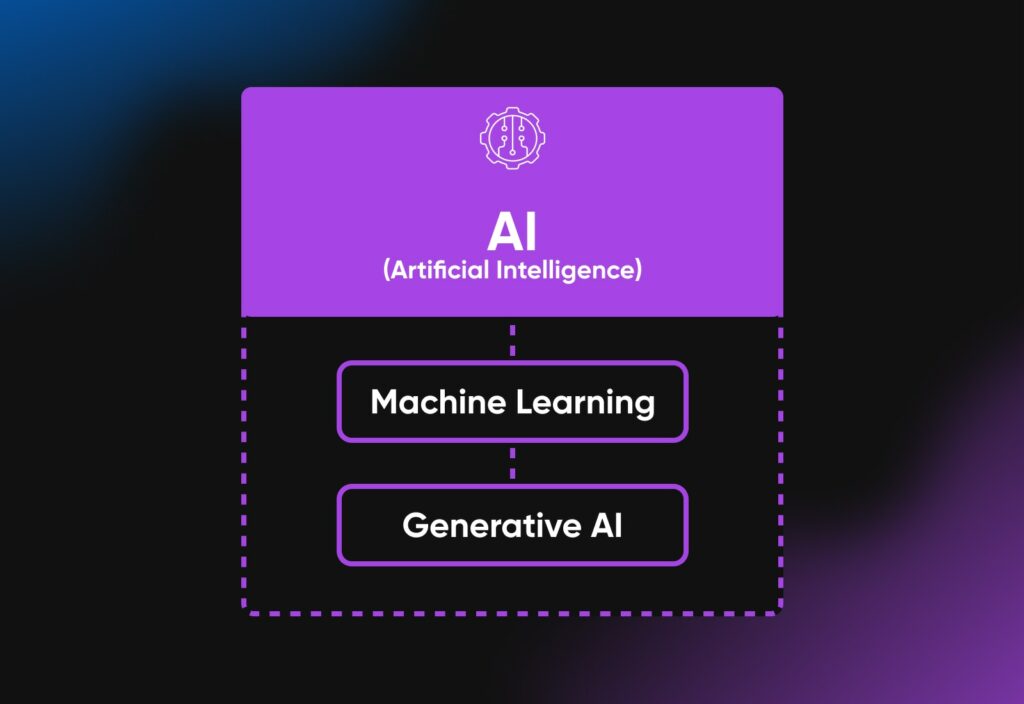
What's the difference between AI, Machine Learning and Generative AI?
Generative AI, AI (Artificial Intelligence), and Machine Learning all belongs to same broad field of Study, but represents a different concept or level of specificity.
Artificial Intelligence is the biggest term among the three. It's about creating machines or software that can think and act like humans. This includes doing tasks that usually require human intelligence and getting better at these tasks with experience. Within AI, there are different areas such as natural language processing (NLP), computer vision, robotics, and machine learning. These are all ways that AI can be used to make machine smarter.
Machine Learning (ML) is a part of AI. It's a way for computers to learn from data and make choices, instead of being told exactly what to do. ML gets better as it sees more data.
Generative AI is like a special kind of machine learning. Imagine it as a model that learns from some data, and then it can create new things that are similar to that data. It's not just about making predictions or decisions based on the data; it's also about being creative and making new, original outputs.
How Does Generative AI Works ?
Generative AI works like a creative person, such as a painter making a new painting or a musician composing a new song. It creates new things based on the patterns it has learned. Imagine learning to draw a cat. You look at many cat pictures and notice things like the body shape, pointy ears, and whiskers. When asked to draw a cat from memory later, you use these patterns to create a new cat picture. It's not an exact copy of any cat you've seen, but a new cat based on the general idea.
Generative AI does something similar. It learns from lots of examples, like images, text, or music. The AI studies these examples to learn the patterns and structures in them. When it learns enough, it can create new examples that are similar.
For example, an AI trained on cat images could make a new cat picture, or one trained on text could write a paragraph about a cat that sounds human. These creations aren't exact copies but new pieces that follow the patterns it learned. The key thing is that generative AI doesn't just copy; it creates new things based on what it learned. That's why it's called "generative" AI.
Data Analytics, also known as the Science of Data, has various types of analytical methodologies, But the very interesting part of all the analytical process is collecting data from different sources. It is challenging to collect data while keeping the ACID terms in mind. I'll be sharing a few points in this article which I think is useful while learning the concept of `Web Scrapping`.
The very first thing to note is not every website allows you to scrape their data.
Before we get into the details, though, let’s start with the simple stuff...
What is web scraping?
Web scraping (or data scraping) is a technique used to collect content and data from the internet. This data is usually saved in a local file so that it can be manipulated and analyzed as needed. If you’ve ever copied and pasted content from a website into an Excel spreadsheet, this is essentially what web scraping is, but on a very small scale.
However, when people refer to ‘web scrapers,’ they’re usually talking about software applications. Web scraping applications (or ‘bots’) are programmed to visit websites, grab the relevant pages and extract useful information.
Suppose you want some information from a website. Let’s say a paragraph on `Weather Forecasting`! What do you do?
Well, you can copy and paste the information from Wikipedia into your file. But what if you want to get large amounts of information from a website as quickly as possible? Such as large amounts of data from a website to train a Machine Learning algorithm? In such a situation, copying and pasting will not work! And that’s when you’ll need to use Web Scraping. Unlike the long and mind-numbing process of manually getting data, Web scraping uses intelligence automation methods to get thousands or even millions of data sets in a smaller amount of time.
As an entry-level web scraper, getting familiar with the following tools will be valuable:
1. Web Scraping Libraries/Frameworks:
Familiarize yourself with beginner-friendly libraries or frameworks designed for web scraping. Some popular ones include:
BeautifulSoup (Python): A Python library for parsing HTML and XML documents.
Requests (Python): A simple HTTP library for making requests and retrieving web pages.
Cheerio (JavaScript): A fast, flexible, and lightweight jQuery-like library for Node.js for parsing HTML.
Scrapy (Python): A powerful and popular web crawling and scraping framework for Python.
2. IDEs or Text Editors:
Use Integrated Development Environments (IDEs) or text editors to write and execute your scraping scripts efficiently. Some commonly used ones are:
PyCharm, Visual Studio Code, or Sublime Text for Python.
Visual Studio Code, Atom, or Sublime Text for JavaScript.
3. Browser Developer Tools:
Familiarize yourself with browser developer tools (e.g., Chrome DevTools, Firefox Developer Tools) for inspecting HTML elements, testing CSS selectors, and understanding network requests. These tools are invaluable for understanding website structure and debugging scraping scripts.
4. Version Control Systems:
Learn the basics of version control systems like Git, which help manage your codebase, track changes, and collaborate with others. Platforms like GitHub and GitLab provide repositories for hosting your projects and sharing code with the community.
5. Command-Line Interface (CLI):
Develop proficiency in using the command-line interface for navigating file systems, running scripts, and managing dependencies. This skill is crucial for executing scraping scripts and managing project environments.
6. Web Browsers:
Understand how to use web browsers effectively for browsing, testing, and validating your scraping targets. Familiarity with different browsers like Chrome, Firefox, and Safari can be advantageous, as they may behave differently when interacting with websites.
7.Documentation and Online Resources:
Make use of official documentation, tutorials, and online resources to learn and troubleshoot web scraping techniques. Websites like Stack Overflow, GitHub, and official documentation for libraries/frameworks provide valuable insights and solutions to common scraping challenges.
By becoming familiar with these tools, you'll be equipped to start your journey into web scraping and gradually build upon your skills as you gain experience.
1
2




